Hemera Featured in Stanford Blockchain Review: The Programmable and Verifiable Data Layer for Internet 3.0
Introduction
The future of the internet is data-hungry, driven by demands from AI innovations. However, the usable data on today’s internet is far from sufficient to meet these AI demands, primarily because users' data is locked inside walled gardens. Blockchains provide the much-needed technology to address this issue, allowing developers to access more usable data with consent. As web3 grows [1], usable data will bypass web2, powering the future of the AI-driven internet with ownership rights, privacy, and incentive alignment as built-in features [2].
Yet, one significant gap remains unresolved—blockchains are NOT built for the large-scale data operations needed to transform on-chain data into a format ready for AI usage (Figure 1). In this article, we propose that a programmable and verifiable data layer, performing computations off-chain, is essential for building decentralized applications and is the key to unlocking the AI-powered internet.

Decentralized Applications’ Server-client Architecture
Decentralized Applications (Dapps) are applications built on top of blockchains. Typically, this means that some, if not all, of the application logic operates on-chain in the form of smart contracts running on validator nodes. Users interact with Dapps through transactions generated by these smart contracts, which are then recorded on the blockchain network. Some important user data is recorded directly on blockchains, while other data is stored off-chain but can be attributed through blockchain records. Blockchains are openly accessible from both a read and write perspective: users pay gas fees to "write" data on-chain, and anyone can "read" the data and track how it has changed over time. In contrast, Web2 applications manage user data through centralized application servers and databases, where only the controlling entity can decide who has access to the application and its data (Figure 2).

The architectural differences of Dapps lead to distinct scaling and security challenges in both the "write" and "read" paths of blockchains. As we will discuss in this article, the "read" path faces significant scalability and verifiability challenges, making a new protocol standard urgently needed.
The Write Path
Improving the write path has been the central theme of crypto infrastructure development: how to write more cheaply, quickly, securely, and conveniently.
Efforts to scale blockchains began during Bitcoin's famous "Blocksize War" [3], during which "larger blockers" attempted several times to increase Bitcoin’s 1MB block size to achieve higher transaction throughput. This led to a split within the Bitcoin community and the creation of several altcoins, with Bitcoin Cash ($BCH) being one of the more notable examples. Ethereum was later created as "Bitcoin plus smart contracts" [4], allowing developers to build applications that write more diverse types of data to blockchains.
After DeFi summer, Ethereum's mainnet became congested, and the rollup-centric roadmap was adopted as the scaling solution for the Ethereum community [5]. Rollups are designed to offload a significant portion of data writes from the mainnet, reducing the data stored on Ethereum and creating more blockspace to increase overall write throughput. Ethereum’s recent Dencun upgrade [6] introduced temporary on-chain storage called "blobs," allowing rollups to reduce gas fees by an order of magnitude [7].
Each rollup hosts its own set of states, which means that even the same Dapp deployed on different rollups will have completely separate data sets. This causes fragmentation issues for both users and developers. For users, even the same token will have different and unrelated balances on different rollups. As a result, users must transfer tokens using bridges between chains, while keeping track of gas tokens. For developers, Dapps are now operating on multiple application servers and databases, each of which requires additional engineering work to develop and maintain in order to provide a cohesive user experience.
Reducing friction for cross-chain activities has become a major focus for improving the user experience within modular ecosystems. Zero-Knowledge Proofs (ZKP) provide a cryptographically secure way to allow computations and resulting state changes on one blockchain to be verifiable on another. Projects like Polygon’s Agglayer [8] rely on ZK-powered security to enable chains to securely send transactions to each other. While secure, ZKP is currently bottlenecked by high computational costs and long proof times. To improve user experience and reduce finality time, some ZK developers focus on optimizing the ZKP stack: Prover Network projects like Snarkify [9] focus on GPU acceleration to reduce proving time and costs, while Prover Aggregation projects like Nebra [10] aggregate ZKPs to achieve economies of scale.
ZKP is not the only solution to the fragmentation issue. Shared security mechanisms enabled by restaking protocols [11] provide a strong crypto-economic way to build a system with a robust Proof-of-Stake (PoS) consensus mechanism. AltLayer’s MACH product [12] is the first in the market to enable fast finality at low cost by leveraging restaking mechanisms.
Despite the growth of rollups, the throughput of the Ethereum ecosystem is still far from reaching internet-scale usage [13]. The Ethereum Virtual Machine (EVM), being the most widely adopted protocol standard, is due for significant performance upgrades [14]. Various projects are working to improve blockchain "write" throughput. Monad [15], for instance, tackles this challenge by rebuilding Layer 1 from the ground up, introducing novel execution and consensus layers while maintaining compatibility with the EVM protocol standard. Others, like MegaETH [16], take a different approach by optimizing centralized sequencers while relying on Ethereum mainnet’s decentralization and anti-censorship properties.
Regardless of which approach or project ultimately dominates the market, one thing is clear: blockchains are soon poised, in terms of write performance, to support a new wave of Dapps. This, in turn, will attract millions of users and lead to exponentially more on-chain transactions in the near future.
The Read Path
Compared to the write path, there are far fewer protocol standards currently being developed for the read path. However, as we will discuss in this section, the read path has impacts on user experience that are just as significant as the write path. Additionally, it presents a major challenge for developers to build in-house.
The Challenges of Off-chain Data Transformation
There is no direct mapping between transaction hashes and relevant accounts on the blockchain. As a result, developers rely on off-chain databases to transform on-chain transactions into the desired values.
The first challenge is data integrity, which is at risk by each additional engineering step introduced to process data off-chain. The challenge multiplies when developers build Dapps on multiple chains, each adding another layer of complexity to ensure data integrity.
Transaction data transformation is engineeringly heavy and primarily driven by the heterogeneous nature of smart contracts. As we will discuss in this section, depending on the design choices made by smart contract developers, critical information is often conveyed through "logs" and "internal transactions," which are recorded in "traces" (see Figure 3).
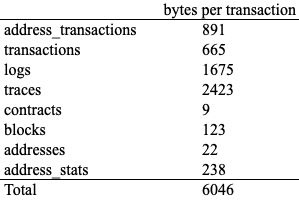
Ethereum smart contracts store data in two ways: account storage and logs. Account storage contains states and is directly accessible by the smart contracts themselves. Logs, on the other hand, are designed to be significantly less costly in terms of gas than contract storage, but as a trade-off, they are not directly accessible by smart contracts. For comparison, logs cost 8 gas per byte, whereas contract storage costs 20,000 gas per 32 bytes, or approximately 625 gas per byte, making contract storage ~78 times more expensive than logs. Logs are created during the execution of smart contracts, and the resulting log data is written and recorded as part of each transaction.
Depending on the purpose of the smart contract, developers may choose to store important data in logs, which are essential for a variety of prominent use cases. Logs are crucial for Dapp developers to display contract interactions, track user activities, and handle potential errors. Additionally, logs play a key role in contract auditing, anomaly detection, and other security-related use cases. They are also invaluable for gaining insights into market dynamics and user behavior.
Internal transactions are transactions initiated by the contract itself, rather than by an externally owned account (EOA). Common use cases include programmatically distributing assets to multiple accounts (both contract and EOA accounts) and executing complex trading strategies. Internal transactions are vital for a range of use cases, including tracing asset movement, calculating trading volume, and determining profit and loss.
The vast design space of smart contracts makes logs and internal transactions highly heterogeneous and difficult to compute. Therefore, the ideal solution, without limiting smart contract developers' flexibility, is to establish an abstraction layer standard that helps developers extract and restore semantics from transaction data. The proposed protocol should:
- Provide a clean interface for developers to plug in data transformation logic.
- Be open-sourced and portable across the developer community.
- Be verifiable by anyone.
- Be secured through cryptographic methods.
How Does Hemera Tackle the Challenges?
Hemera addresses these challenges through its Account-Centric Indexing protocol, which introduces two key innovations:
- User-Defined Functions (UDFs): Programmability via a simple functional interface
- History Transparency AVS: Verifiability to ensure data integrity
Programmability
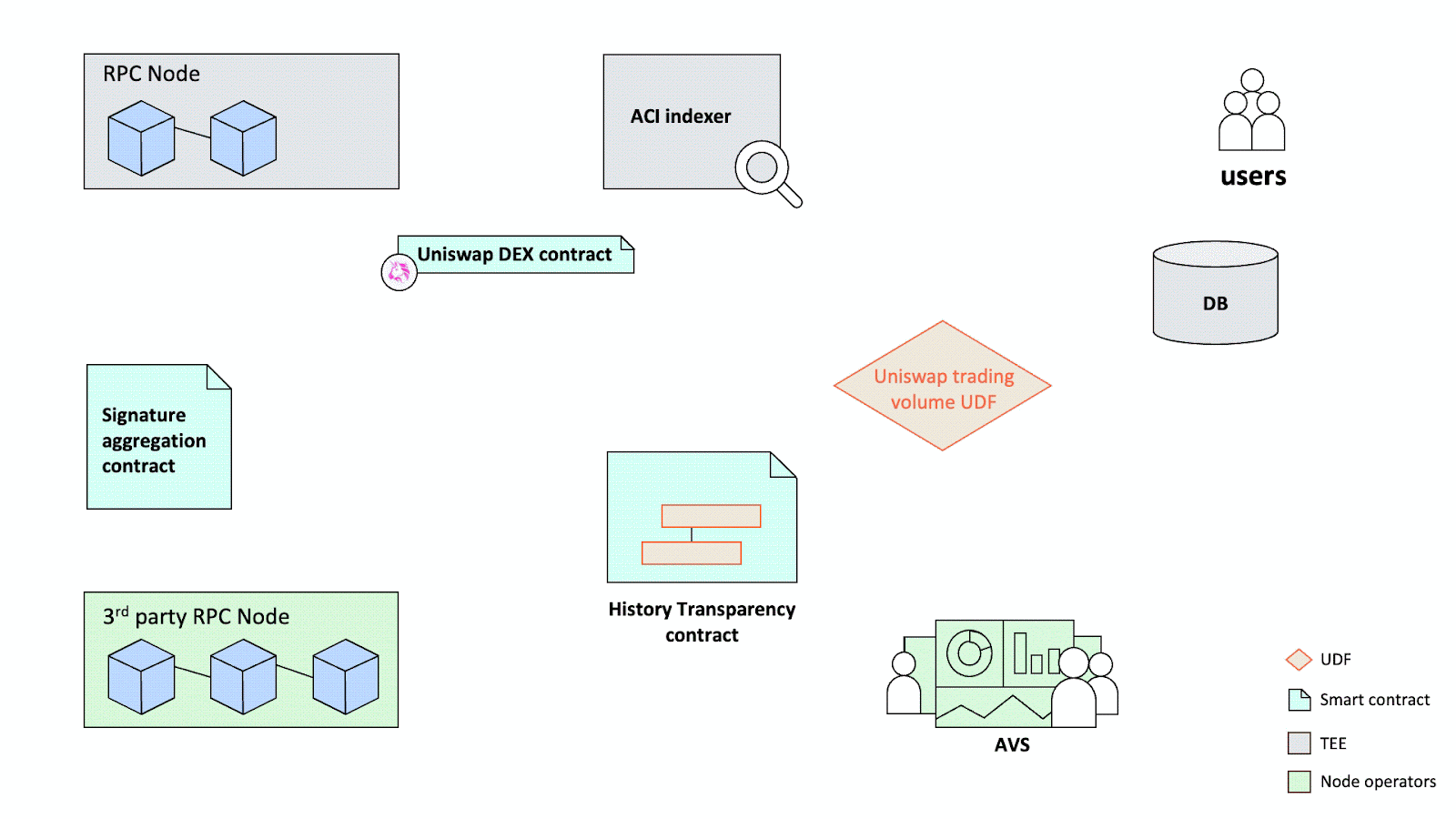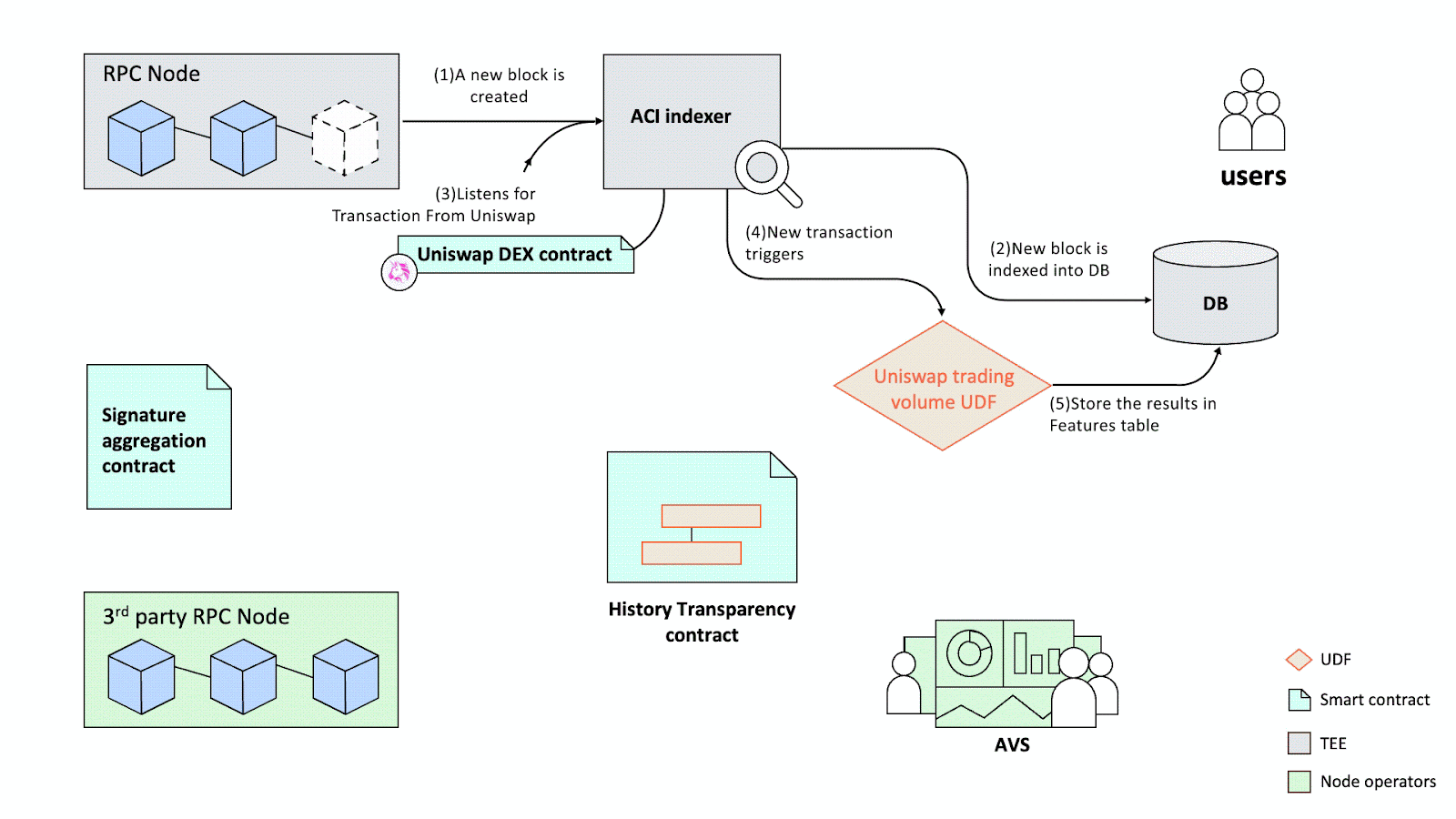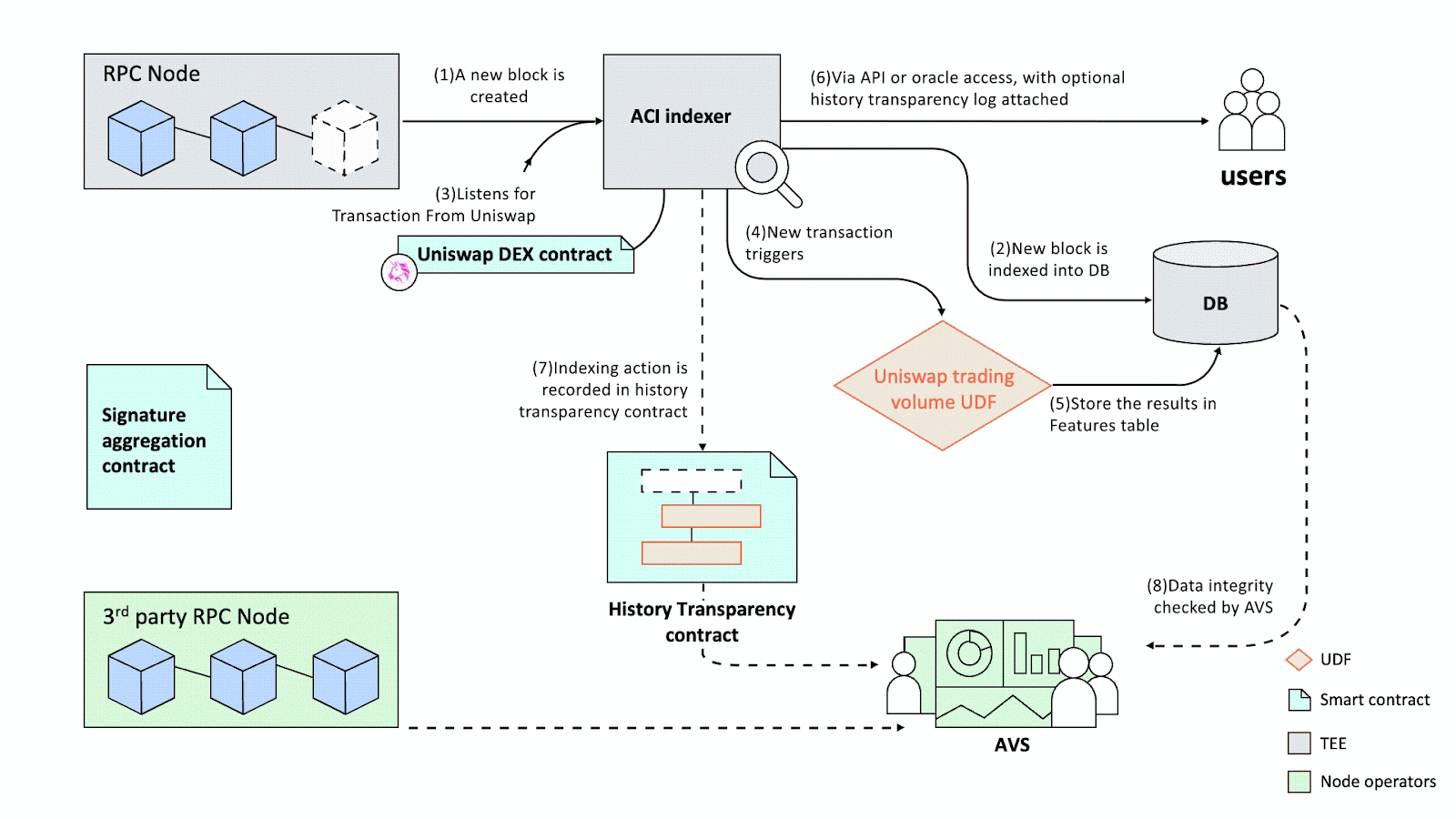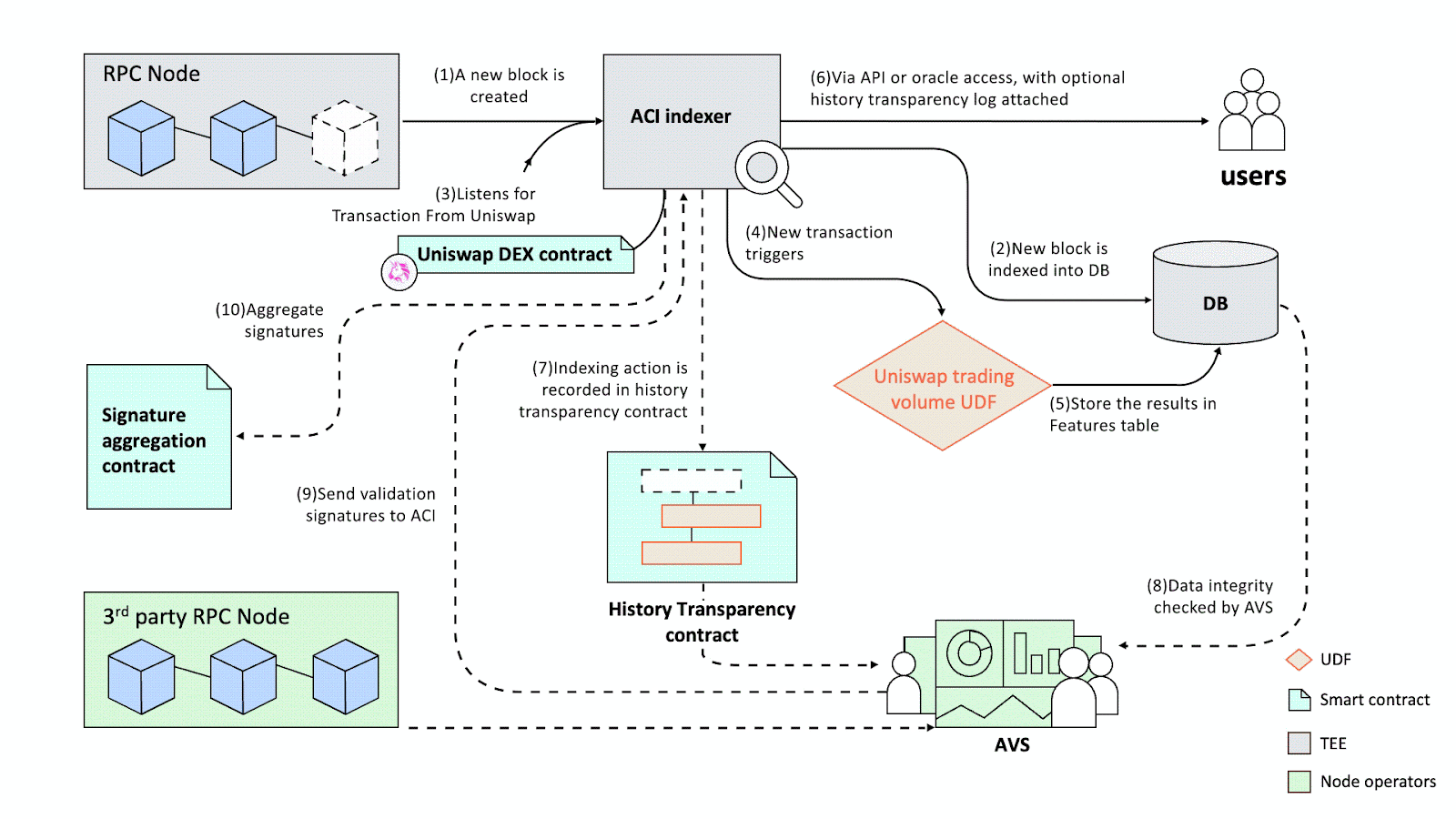
The Account-Centric Indexing (ACI) Protocol offers strong programmability through a functional interface called User-Defined Functions (UDFs). The outputs of UDFs are values defined by the developers (see Figure 4).
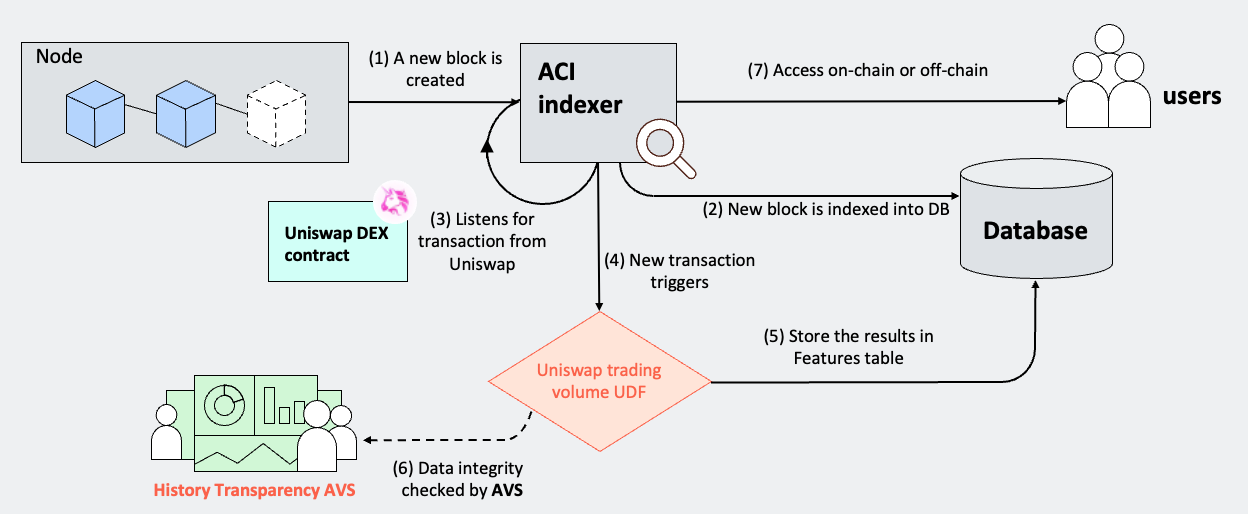
UDFs take transactions as inputs and can be configured to compute across one or multiple smart contracts. Anyone can develop UDFs and deploy them to the ACI protocol network. The network manages the life cycle of the UDFs, allowing them to process transactions as configured and generate or update the output values, known as Features, for the affected accounts (see Figure 5).
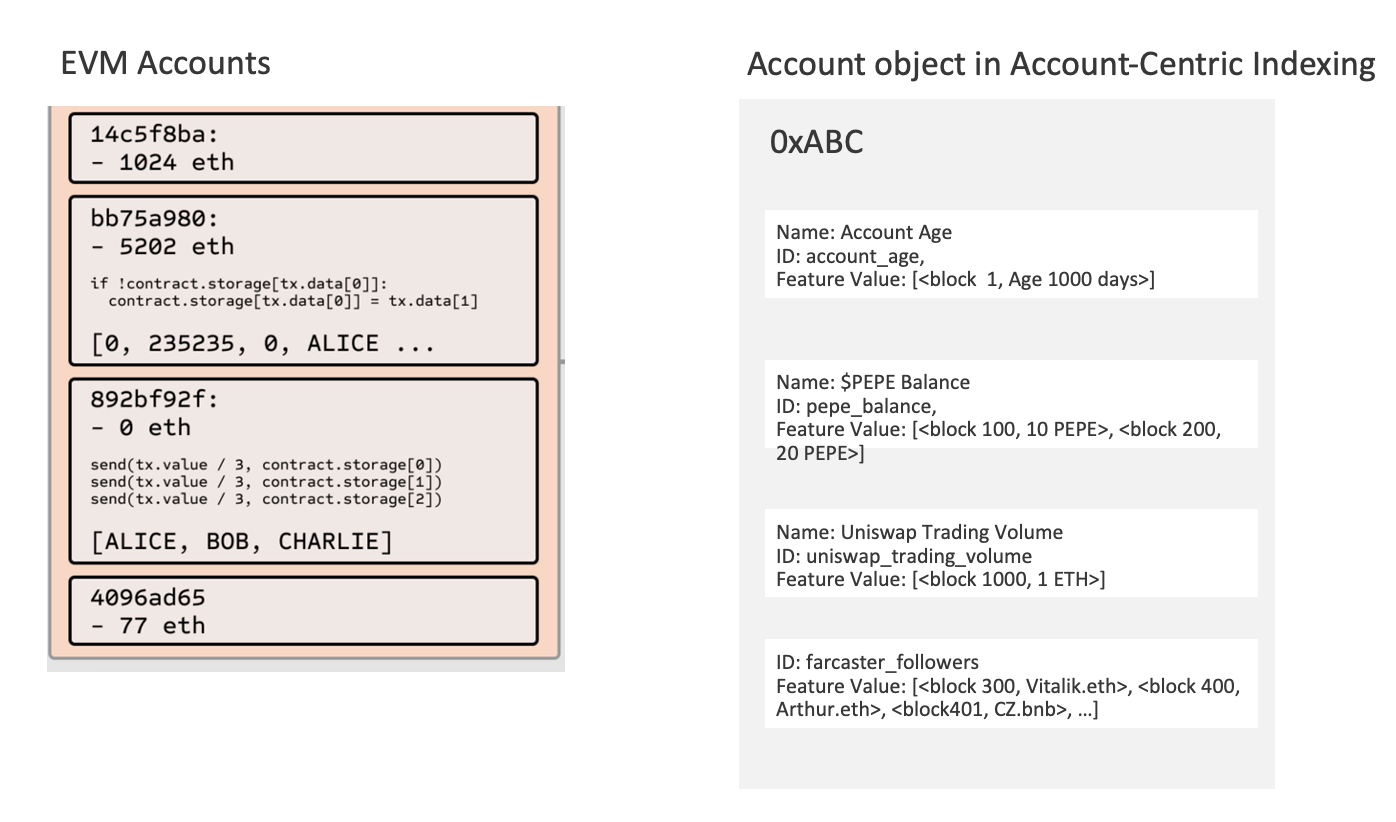
Users utilizing the Features generated by UDFs do not need knowledge of raw transactions or the underlying smart contract logic, allowing them to focus on building their own applications [17]. When users require programmability to create their own Features, UDFs provide a simple functional interface to achieve this goal. Upon the mainnet launch of the ACI protocol network, a built-in UDF library, contributed by both the Hemera team and the broader UDF developer community, will operate in real-time by default, computing Features for each impacted account. Additional technical benefits of the UDF design include portability, high modularity, easy testing, and verifiability.
Verifiability
One of the underrated challenges faced by indexing providers is ensuring data integrity—how to verify that the indexed data in off-chain databases is 100% correct compared to the on-chain records, which serve as the single source of truth. Here, verifiability means allowing third parties to perform end-to-end verification of the integrity of raw transactions and post-processed values.
The data integrity problem is complex due to various factors, including:
- Blockchain finality: It takes about 15 minutes for an Ethereum block to finalize [18]. Before finalization, blocks are temporary, and indexers need to update their state once blocks are finalized. Different blockchains have different finality times, which indexers must handle accordingly.
- Faulty RPC providers
- ETL issues: Engineering issues in the Extract, Load, and Transform (ETL) process can cause missing or corrupted data.
- Compromised indexers by external hackers: External hackers may tamper with indexed data.
- Internal hacks: Malicious activities by project team members or compromised internal developer servers can threaten data integrity.
Hemera proposes a verification system called “History Transparency” to provide a crypto-economic guarantee of the ACI protocol network’s data integrity. The design was inspired by Google’s Certificate Transparency system (Certificate Transparency). The core idea is to store an "append-only" log on the blockchain—within the History Transparency contract—for each database update action, including block indexing and UDF computations. This contract records essential information, such as the source blockchain ID, block number, and timestamp, allowing anyone to verify the ACI protocol network’s data integrity. A network of decentralized validators verifies data integrity by comparing the byte-level correctness of each datum with on-chain history. These validators are secured crypto-economically by their stakes, and their aggregated signatures generate a consensus on the integrity verification (Figure 6).
Bootstrapping a consensus mechanism is traditionally very challenging. Proof-of-Stake (PoS), the prevailing consensus mechanism for infrastructure projects, requires developers to compete for stakers against larger ecosystems. Hemera leverages the shared security mechanism of the EigenLayer restaking protocol to build the PoS mechanism. Hemera is one of the first projects to create an Actively Validated Service (AVS) for validating off-chain computations [19].
Another option is to leverage ZKP, which is theoretically capable of providing the necessary verification and supporting the programmability of UDFs through the ZK virtual machine (zkVM). A good example is ZK coprocessors like Brevis [20] and Axiom [21], which use the Merkle tree root hash to validate raw transactions and ZKP to perform computations, trading off latency and costs for the same security guarantees as on-chain computation while maintaining high data integrity. However, for the majority of use cases Hemera aims to support, forcing all computations through the zkVM introduces too much computational overhead for insufficient value. Instead, ZK coprocessors can complement Hemera in specific "high value, low volume" use cases, where the reward for using ZKP outweighs the computational overhead.
Hemera Prioritizes Scalability, Programmability, and Security Over Decentralization
Hemera’s ACI protocol is designed to be a read path protocol that supports internet-scale scalability while being secure enough to guarantee data integrity. When considering the design choices behind ACI, it is helpful to use the scalability trilemma [22] as a framework, particularly in comparison to blockchain systems. Hemera’s ACI prioritizes scalability, programmability, and security over decentralization for the reasons explained below.
It’s important to note that the trilemma was originally used to evaluate scalability challenges in blockchain systems, but since the read path primarily occurs off-chain, the definitions differ slightly in this context:
- Decentralization: Defined as the ability for each participant to operate with limited resources, such as a regular laptop or desktop. In the context of the read path, decentralization mainly means that any participant can join the protocol to assist with indexing or post-processing computations.
- Scalability & Programmability: Defined as the ability to read on-chain data with high throughput, low latency, and strong computational performance during data post-processing. A highly scalable read path protocol can read every transaction from any blockchain, compute thousands of values from them, and return the results with sub-second latency.
- Security & Integrity: The security model for the read path protocol follows a "1 out of n" model, as opposed to blockchain’s "1/n" model [23], meaning the system only requires one good actor to ensure security. Unlike blockchain systems, where decentralization plays a central role, data integrity is equally important for security in a read path protocol. Data integrity is defined as the protocol’s ability to read and compute data with 100% accuracy based on on-chain records.
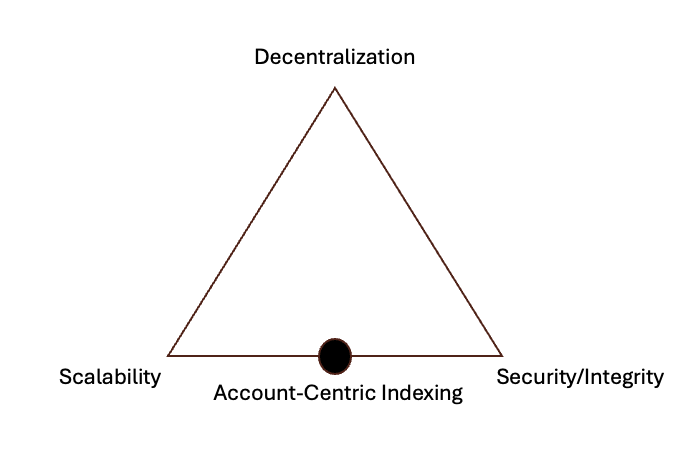
The decentralization aspect is constrained by the laws of physics—supporting an internet-scale ACI protocol network with uncompromising guarantees for latency, throughput, uptime, and data integrity sets a very high bar for operators in terms of the computing power needed to meet these performance requirements. In future mainnet versions, a sufficiently decentralized protocol network, operated by a handful of entities, can enhance the ACI protocol’s decentralization.
The UDF abstraction layer is designed to maximize scalability and programmability, allowing developers to flexibly access semantic data in real time from any account and any chain supported by the ACI protocol. UDFs are portable by design, incentivizing community developers to contribute to UDF development through the protocol’s utility tokens. High-quality UDF development will be rewarded with one-time incentives and continuous revenue shares.
The History Transparency system is designed to ensure security and data integrity. This system allows anyone in the community to verify and submit challenges regarding data integrity. If any data correctness issues arise, community members can verify the problem by comparing the indexed data to the on-chain records. Community members and protocol users are incentivized with utility tokens to submit verification challenges, helping to detect and resolve data integrity issues. The ACI protocol network’s security is thus guaranteed by the History Transparency AVS’s crypto-economic security mechanism.
Why Does a Verifiable "Read” Path Protocol Matter?
This section explores several real-world use cases. In short, improving the "read” path by building a public goods infrastructure can unlock a wide range of utilities powered by crypto data.
Blockchain-based Identity and Reputation System
One of the most important use cases is enabling a neutral blockchain-based reputation system [24]. Since Ethereum's inception, numerous identity and reputation protocols have been developed, including:
- On-chain name registration systems like ENS [25]
- Attestation protocols such as EAS [26]
- Non-transferable token reputation systems known as "soulbound" tokens [27]
- On-chain quest-based credential platforms [28]
- ZKP-empowered on-chain passports like Zupass [29]
These protocols can be broadly categorized into two types: identifiers and credentials, which together form blockchain-based identity. The permissionless nature of blockchains will continue to drive developments in this area, enriching the ecosystem with more identifier and credential systems.
Hemera can serve as a neutral identity and credentials aggregator, actively indexing users' credentials across Dapps and chains, and keeping them updated in real time. This blockchain-based identity layer, when combined with ZKP technology and attestation protocols, can be leveraged to support various novel use cases that were previously infeasible. One example is the creation of an omni-chain reputation score, designed to help Web3 builders and communities manage airdrops [30].
The need for such a neutral identity layer arises from the decentralized account system in Web3, which makes most of the trust and safety technologies widely adopted in Web2 not directly applicable in Web3. This leaves builders vulnerable to Sybil attacks, where malicious actors can exploit decentralized systems to farm millions of dollars worth of token airdrops intended for legitimate users. Builders spend excessive time and resources fighting Sybil attacks, and even some of the most well-funded projects struggle with this issue [31].
The proposed neutral identity layer enables the adaptation of many existing Web2 technologies to help mitigate Sybil attacks in Web3. Additionally, this identity layer can provide valuable insights into the quality of communities and projects, incentivizing good user behavior—something much needed in today's industry, where metrics like Unique Active Wallets (UAW) and transaction counts can be easily manipulated.
Personalized Recommendation Algorithms and AI Agents
One of the main issues with social media platforms today is the centralized nature of recommendation algorithms. A potential solution is to build decentralized protocols that allow users to choose from a library of recommendation algorithms based on their preferences [32]. As Web3 continues to gain traction in consumer Dapps—including NFTs, GameFi, and SocialFi—an increasing number of users’ preferences are being recorded on-chain across various Dapps and blockchains in the form of transactions.
The Hemera protocol converts raw on-chain transactions into semantic values that can be utilized to build recommendation algorithms. Since blockchains can attribute and incentivize individual data owners through wallet addresses, builders can create new business models and products in this space, allowing data users to take a share of the revenue generated by AI.
One particularly interesting area is the development of AI agents that act as personal crypto analysts. Based on users' preferences and on-chain activities, these AI agents can monitor and summarize related on-chain dynamics 24/7, generate portfolio reports, and offer recommendations. Such agents can be further enhanced with essential off-chain data, including white papers, smart contract source code, audit reports, security risk signals, and social media feeds (e.g., Twitter).
Conclusion
The lack of a standardized “read” path protocol has become a major architectural challenge for developers building on blockchains. Without a programmable and verifiable “read” path protocol, developers are forced to build in silos, end users are left confused by fragmented information, and the industry suffers from issues like Sybil attacks and the lack of proper metrics to incentivize normal user behavior. Mass adoption remains an unfulfilled promise.
Hemera proposes the Account-Centric Indexing protocol, creating a programmable and verifiable public goods data layer to serve as the “read” path standard. Hemera empowers a wide range of AI and machine learning use cases, including the creation of a universal reputation layer for every on-chain user and essential on-chain data “read” capabilities needed by virtually all Web3 developers.
About the Author
Arthur Meng is the CEO and Co-founder of Hemera. He earned his PhD in Physics from Stanford. Previously, Arthur was a serial entrepreneur in big data and AI, building and selling AI software to large corporations like American Express, Pinterest, Tencent, and Alipay, helping these companies combat Sybil attacks and identify power users. While at Stanford, Arthur became deeply interested in AI and published his work in Nature as a co-first author. You can follow him on X @arthurcmeng.
Hemera is building a programmable & verifiable data layer powered by a novel Account-Centric Indexing protocol. Hemera helps developers abstract the heterogeneity of smart contracts, allowing them to express new semantics through User-Defined Functions (UDFs). Hemera has been deployed to support 20+ EVM chain ecosystems, including notable chains such as Story, ZetaChain, Taiko, Manta Pacific, Morph, and Mantle Network. You can follow Hemera on Twitter @HemeraProtocol.
Special thanks to Lei Yang from MegaEth, Junda Liu from Celer Network, Ouyang from Snarkify for their discussion and feedback on the protocol design.
References
- Dixon, C. (2024). Read Write Own: Building the Next Era of the Internet. Random House Publishing Group.
- Story. (2024, 10 1). Story: The World’s IP Blockchain. Stanford Blockchain Review. https://review.stanfordblockchain.xyz/p/51-story-the-worlds-ip-blockchain
- Bier, J. (2021). The Blocksize War: The Battle Over Who Controls Bitcoin's Protocol Rules. Amazon Digital Services LLC - Kdp.
- Buterin, V. (2023, December 28). Make Ethereum Cypherpunk Again. Vitalik Buterin's website. Retrieved October 17, 2024, from https://vitalik.eth.limo/general/2023/12/28/cypherpunk.html
- Buterin, V. (2021). An Incomplete Guide to Rollups. An Incomplete Guide to Rollups. Retrieved Jan 5, 2021, from https://vitalik.eth.limo/general/2021/01/05/rollup.html
- Cancun-Deneb (Dencun) FAQ | ethereum.org. (2024, March 13). Ethereum. Retrieved October 17, 2024, from https://ethereum.org/en/roadmap/dencun/
- Wang, L. (2024, April 24). Post EIP-4844 — The Primary Factors Impacting Gas Fees on Layer 2 Blockchains. Medium. Retrieved October 17, 2024, from https://medium.com/hemera-protocol/post-eip-4844-the-primary-factors-impacting-gas-fees-on-layer-2-blockchains-df64799d28ec
- Farmer, B. Liquidity, unified. Polygon Technology. Retrieved October 17, 2024, from https://polygon.technology/agglayer
- Snarkify: https://snarkify.io/
- NEBRA Labs. Retrieved October 17, 2024, from https://nebra.one/
- EigenLayer: https://www.eigenlayer.xyz/
- AltLayer (ALT): from https://www.binance.com/en/research/projects/altlayer
- a16z Crypto. (2024, 10 16). State of Crypto Report 2024: New data on swing states, stablecoins, AI, builder energy, and more. a16z crypto.
- The AMM Test: A No BS Look at L1 Performance. (2022, March 1). Medium: from https://medium.com/dragonfly-research/the-amm-test-a-no-bs-look-at-l1-performance-4c8c2129d581
- Monad : from https://www.monad.xyz/
- MegaETH: from https://megaeth.systems/
- Hemera & Meng, A. (2024, 9 1). Hemera Whitepaper: https://docs.thehemera.com/hemera-indexer/introduction
- Ethereum. (n.d.). Single slot finality | ethereum.org. Ethereum. Retrieved October 22, 2024, from https://ethereum.org/en/roadmap/single-slot-finality/
- Altlayer. (2024, 10 3). GoPlus and Hemera to be the first to launch AVSs on AltLayer’s AVS-as-a-Service platform “Wizard”. Medium. https://blog.altlayer.io/goplus-and-hemera-to-be-the-first-to-launch-avss-on-altlayers-avs-as-a-service-platform-wizard-d817e9fa84c8
- Brevis Network. (2024, 2 26). Launching Brevis V2: Generalized ZK Coprocessor for Data-driven dApps. Brevis Network. Retrieved October 17, 2024, from https://blog.brevis.network/2024/02/26/v2launch/
- Axiom: from https://www.axiom.xyz/
- Buterin, V. (2017, December 31). Sharding FAQ. Vitalik Buterin's website. Retrieved October 18, 2024, from https://vitalik.eth.limo/general/2017/12/31/sharding_faq.html#this-sounds-like-theres-some-kind-of-scalability-trilemma-at-play-what-is-this-trilemma-and-can-we-break-through-it
- Buterin, V. (2020, August 20). Trust Models. Trust Models. Retrieved October 18, 2024, from https://vitalik.eth.limo/general/2020/08/20/trust.html
- Buterin, V. (n.d.). Ethereum Whitepaper | ethereum.org. Ethereum. Retrieved October 17, 2024, from https://ethereum.org/en/whitepaper/
- ENS Domains: from https://ens.domains/
- Ethereum Attestation Service, EAS: from https://attest.org/
- Ohlhaver, P., & Kavanagh, D. (2022, May 11). Decentralized Society: Finding Web3's Soul by Puja Ohlhaver, E. Glen Weyl, Vitalik Buterin. SSRN. Retrieved October 17, 2024, from https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4105763
- Galxe. Galxe - Onboarding the World to Web3: from https://www.galxe.com/
- Zupass: https://zupass.org/
- Buterin, V. (2024, 8 28). X post. X. https://x.com/VitalikButerin/status/1828727585204842867
- Pellegrino, B. (2024, June 16): from https://x.com/PrimordialAA/status/1802260854970171748
- Dorsey, J. (2019, 12 11). Twitter's decentralized future. X. https://x.com/jack/status/1204766090858909696